the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 17 Jun 2022
| 17 Jun 2022
Technical note: Graph-theory-based heuristics to aid in the implementation of optimized drinking water network sectorization
Marius Møller Rokstad
Karel Laarhoven
Drinking water distribution networks form an essential part of modern-day critical infrastructure. Sectorizing a network into district metered areas is a key technique for pressure management and water loss reduction. Sectorizing an existing network from scratch is, however, an exceedingly complex design task that designs in a well-studied general mathematical problem. Numerical optimization techniques such as evolutionary algorithms can be used to search for near-optimal solutions to such problems, but doing so within a reasonable time frame remains an ongoing challenge. In this work, we introduce two heuristic tricks that use information of the network structure and information of the operational requirements of the drinking water distribution network to modify the basic evolutionary algorithm used to solve the general problem. These techniques not only reduce the time required to find good solutions but also ensure that these solutions better match the requirements of drinking water practice. Both techniques were demonstrated by applying them in the sectorization of the actual distribution network of a large city.





Drinking water distribution systems (DWDSs) form an essential part of modern-day critical infrastructure. As these large pipe networks are often hard to reach and interwoven with other urban infrastructure, modifying them is an arduous and expensive task. Regardless, drinking water utilities need to consider applying new designs to their networks in order to, for instance, improve service, reduce water losses and to prepare in a resilient way for an uncertain future.
Here, we focus on one specific aspect of network redesign: sectorization. Sectorization entails dividing a DWDS into separate subnetworks, either by closing the boundary pipes between them or by outfitting the boundaries with pumps, pressure reduction valves or flow meters. As a result, the water balance of individual subnetworks or District Metered Areas (DMAs) can be obtained, and the pressures in the DMAs can be managed separately.
In many countries, sectorization into DMAs has been a key strategy for leak detection and water loss reduction through pressure management (UK Water Authorities Association, 2008; Morrison et al., 2007; Farley et al., 2001). In other countries, such as Norway and the Netherlands, however, water utilities have only recently started to consider the advantages of sectorization. Not having integrated sectorization in their network design process at the start, these utilities now face the challenge of designing an efficient division of their complete infrastructure at once. This will involve balancing many different criteria, prime among them the costs of placing or removing network components and the reduction in hydraulic performance that follows from decreased connectivity in the network. Moreover, as DWDSs typically are huge meshed systems, there often are an overwhelming number of different approaches to dividing up the network.
The key challenge of network sectorization lies in finding ways to efficiently divide the network in as many DMAs as possible with as few changes (which are costly) to the network as possible. This essentially is a version of the (np-hard) minimal k-cut problem (Kim et al., 2011). In the past decades, problems such as these have inspired extensive research on the application of numerical optimization techniques to aid in various aspects of DWDS design (Mala-Jetmarova et al., 2018; Maier et al., 2014). The literature contains a multitude of examples of various methods applied to achieve effective sectorization of water distribution networks (Alvisi, 2015; Brentan et al., 2018; Ciaponi et al., 2016; Diao et al., 2013, 2016; Laucelli et al., 2017; Liu and Han, 2018; Hajebi et al., 2015; di Nardo et al., 2014; Vasilic et al., 2020; Zhang et al., 2016, 2017). Such techniques allow drinking water experts to explore their options in a systematic, automated way and to subsequently substantiate their choice for specific, optimal solutions. One particularly versatile technique that has received thorough attention in this context is that of genetic algorithms (GAs) (Holland, 1975; Goldberg, 1989) and other members of the overarching family of evolutionary algorithms (EAs).
While EAs are known to be suitable for sectorization-type problems, one of their limitations is the unreasonable amount of function evaluations required to converge to an optimal solution properly (Kim et al., 2011). Moreover, when it comes to practical application of EAs, improving their searching behaviour in terms of computational speed and quality of results remains an ongoing challenge (Maier et al., 2014; van Thienen et al., 2018). To this end, the various mechanisms of the classic genetic algorithm are commonly expanded, replaced or combined with heuristic tricks or complete heuristic algorithms to improve performance (Maier et al., 2014; Krasnogor and Smith, 2005; El-Mihoub et al., 2006; van Laarhoven et al., 2018). The algorithms which include these are commonly referred to as hybrid genetic algorithms (HGAs) or memetic algorithms (MAs).
In this paper, we report two HGA techniques that have aided in the successful application of EAs for sectorizing real-life DWDSs of large towns in Norway and the Netherlands. Both techniques first use graph theory algorithms to extract aspects of the network structure in a formal way. This information on network structure is used to guide the searching behaviour of the EA towards structures that are preferable in a DWDS according to the criteria of water utility experts. Making the design criteria of utility experts explicit in this way enhances trust in the technique and thereby enhances the chances of practical implementation of numerical optimization. Secondly, computational time required to find suitable solutions is reduced so that practical application becomes feasible.
2.1 Basics of EAs and their application to sectorization
EAs are a type of optimization algorithm inspired by concepts from genetics. The general principle behind this type of algorithm is shown schematically by the blue boxes in Fig. 1. First, a collection of possible solutions is created (a population of individuals). The solutions are tested for their performance according to the user's performance criteria. The least successful solutions are discarded (natural selection), and the collection is supplemented with new solutions. The new solutions are generated by creating small variations in well-performing solutions (mutation) or by combining elements from two well-performing solutions (reproduction or crossover). The process is then repeated several times, gradually improving the quality of solutions (evolution).
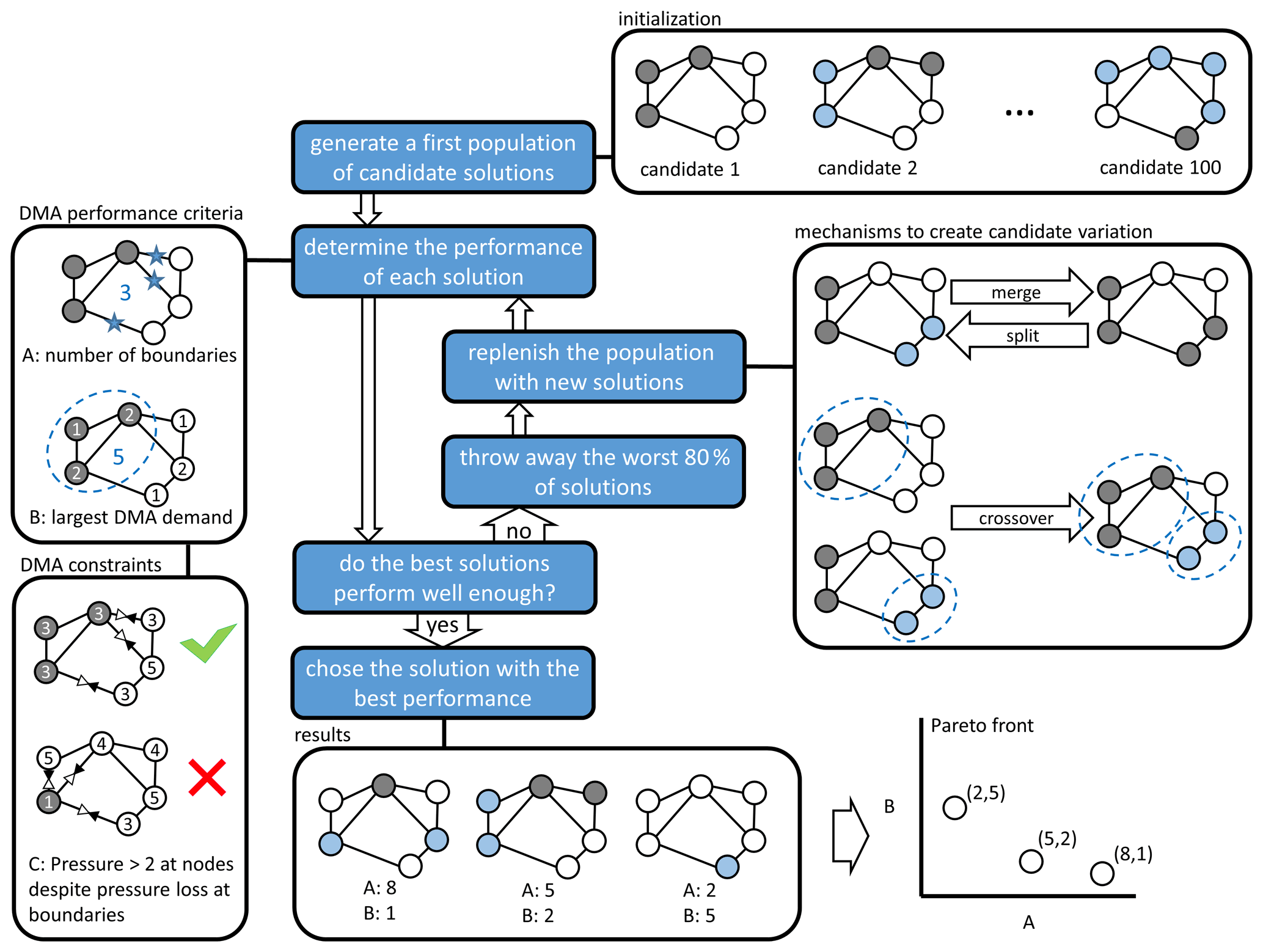
Figure 1Schematic representation of the evolutionary optimization algorithm used. The blue boxes summarize the general operation of the algorithm. The white boxes illustrate a basic implementation of the algorithm used to optimize a DMA configuration.
If individual solutions are judged based on only one performance criterion, selecting the final candidate is a matter of selecting the solution with the highest performance. If multiple performance criteria are used, however, it may occur that these criteria are at odds, so a choice must be made that accepts a trade-off between the two. This trade-off is typically represented by a Pareto front, a graph that scatters individual solutions on two or more axes that correspond to their scores according to the different criteria.
The white boxes in Fig. 1 illustrate a basic way in which an EA can be applied to find solutions to the sectorization problem, i.e. to find ways to divide the network into subnetworks with as few boundaries between them as possible:
-
Initialization. Individual solutions are defined by assigning every demand node in a DWDS to a given DMA.
-
DMA performance criteria. Typical aspects that are important for the performance of a solution are, for instance, the sizes of the individual DMAs and the number of boundaries between them. To determine these aspects, a specific representation of solutions is needed that includes the graph topology of the network. In other words, the solution must contain not only information on the demand nodes of the DWDS but also on the pipes between them. A specific representation may also include more detailed information on the functional properties of the DWDS – effectively forming a complete hydraulic model – so that the hydraulic performance of a solution might be assessed (for instance in terms of reduced supply capacity once a certain pipe between DMAs is closed).
-
DMA performance constraints. Rather than being used as performance criteria that drive the direction of optimization, solution properties may also be made subject to constraints or boundaries. This ensures that networks keep meeting practical requirements while their configuration is changed to optimize the performance criteria. This could be as simple as putting a minimum or maximum on the value of a performance criterion for a solution to be considered viable. Far more complex constraints may be useful or necessary, however. The topic of Sect. 2, for instance, is ensuring that connectivity, redundancy and pressure requirements throughout the network are met when every DMA boundary is outfitted with a pressure reduction valve of a particular setting (a constraint that requires multiple hydraulic simulations to evaluate for a single possible solution).
-
Mechanisms to create candidate variation. Basic mutation can be achieved by splitting DMAs in two or by merging adjacent DMAs. Crossover can be achieved by taking specific DMAs from two solutions to construct a new solution (paying attention to smoothing possible gaps between solutions).
-
Results and Pareto front. The two criteria used here are mutually exclusive, i.e. smaller DMAs are beneficial but require more boundaries to realize, which is not preferred. As such, the individual results should be ordered in a Pareto front from which a solution must then be chosen based on criteria outside the optimization process.
2.2 Shortest independent paths identification algorithm for reliability conservation and search space reduction
One specific reason to sectorize a network may be to divide it into pressure management zones. These are subnetworks, separated by pressure reduction valves, aimed at reducing the pressure throughout the network. In this case, every boundary between zones has an implication for the hydraulic performance of the network. The hydraulics of the network, however, are subject to many practical constraints and, indeed, regulations. It must for instance be ensured that, despite the introduction of pressure reduction valves, the network is able to supply sufficient water not only in the nominal situation, but also during a pipe failure calamity or while a fire hydrant is in use.
Checking whether a particular solution will meet these constraints will require a multitude of hydraulic simulations under different scenarios. The computational time required to verify this could easily be of the order of tens of hours for a single solution when a realistically large distribution network is considered. As such, the time required to check the performance of individuals is prohibitively large for an EA to be used (in which easily millions of individuals need to be evaluated throughout the search). The need to check whether a particular solution for sectorization of the drinking water network will be in violation of the performance requirements set by the utility or legislation has been limiting Trondheim municipality's capacity to optimize their sectorization with respect to pressure management, as the number of hydraulic simulations and computational time would be impractically high, thus making it virtually impossible for the utility to identify a globally effective solution for pressure management. The objective of the algorithm suggested here is to provide an alternative way of ensuring the hydraulic requirements of solutions while optimizing a sectorization with pressure control zones in mind.
The core of the approach is to evaluate to which extent individual nodes in a water distribution system are served by multiple, independent paths, as this is a measure of reliability and system robustness. This is achieved by representing the network as a bi-directional weighted graph, identifying the shortest path between source and demand node using Dijkstra's algorithm, consecutively changing the weights of the graph, and rerunning the shortest-path algorithm so that the paths which are maximally independent are identified.
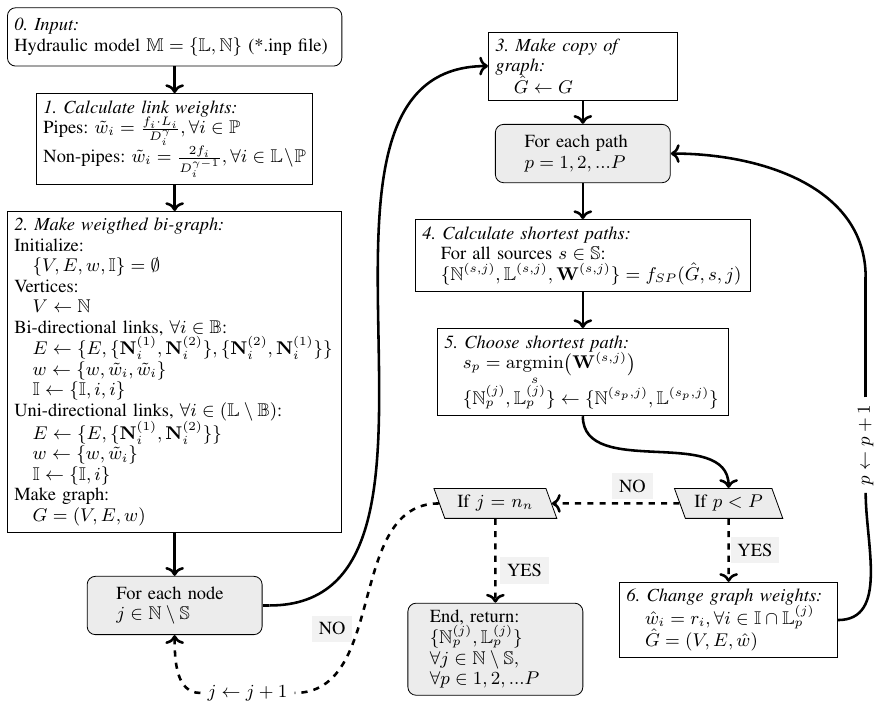
2.2.1 Shortest-path algorithm outline
The suggested procedure for identifying P independent paths in a network is outlined in the flow chart in Fig. 2, and it will be explained further in the following subsections. The method starts with loading the hydraulic model representation M of the network (see step 0 in Fig. 2; the hydraulic model is assumed to contain the following:
-
a set of np links (𝕃) of which P is the subset of links which are pipes (ℙ⊂𝕃), and B is the subset of links which allow bi-directional flow (𝔹⊂𝕃) (as opposed to, for example, check valves). Each link i has defined a first and second node ( and , respectively), a diameter (Di) and a measure of its hydraulic resistance fi=f(ki), where ki is the pipe's absolute roughness); pipes do in addition have a defined length (Li).
-
a set of nodes ℕ, of which 𝕊 is the subset of nodes which are considered sources that can provide water into the system, i.e. reservoirs or water tanks (𝕊⊂ℕ).
Then each link i in the network is assigned a weight according to its hydraulic conductance (step 1):
-
For the set of pipes (ℙ⊂𝕃), the weight is calculated to be proportional to the length (Li) and some measure of the hydraulic resistance (fi), and it is inversely proportional to some exponent of the diameter () of the pipe. In this way, each pipe is assigned a weight according to its hydraulic resistance .
-
The weight for non-pipe links (valves and pumps; 𝕃∖ℙ) is calculated in the same way, with the assumption that its length is twice its diameter, as is also assumed for open valves in EPANET (Rossman, 2000), i.e. .
Based on these weights, a weighted bi-directional graph, G, representation of the network is constructed (step 2) in the following way:
-
each hydraulic node is represented as a graph vertex, i.e. V←ℕ;
-
all bi-directional links (i.e. all links which allow flow in both directions; 𝔹⊂𝕃) are represented as two edges in the graph, with one for each direction (one from to and one from to if i∈𝔹);
-
all unidirectional links (i.e. all links which allow flow in only one direction; 𝕃∖𝔹) are represented as one edge.
After the weighted graph has been constructed, one can start identifying paths for each node in the network. For each node j which is not considered a source (), the following steps are undertaken.
- 3.
A copy of the graph is made, i.e. .
- 4.
For each path p=1, 2 … P, the shortest paths from all sources 𝕊 to nodes j are identified. The function represents applies Dijkstra's algorithm for finding the shortest path between node j and s in the graph . The function fSP returns ℕ(s,j), 𝕃(s,j) and W(s,j), which is the set of nodes, set of links and the sum of weights (total distance) in the path between s and j, respectively.
- 5.
Then, the shortest of the paths between 𝕊 and j is chosen as the p shortest path, i.e. .
- 6.
If the number of paths to be identified for node j has not been reached (p<P), all the weights of the links that are in the current shortest path (going in both directions, thus are changed to the value ri, where , thus ensuring that a path going through any one of the elements in will have a higher weight than any non-looped path that does not go through any of the elements, and thereby prompting the shortest-path algorithm to minimize the number of elements it has in common with the elements in . The algorithm then returns to identify the next (p+1) shortest path for node j. If the number of paths to be identified for node j has reached P, the algorithm moves to the next node (j+1).
Thus, by identifying the shortest path between two nodes, changing the weights of the edges in this path to a value that is larger than the longest possible path in the graph (), and then running the algorithm to find the shortest path again with these changed weights, the shortest-path algorithm will identify a path that is as independent as possible from the paths that have already been identified.
2.2.2 Performance metrics for independent paths
When the P independent paths for a set of nodes in a network have been identified, one can utilize these paths to assess aspects of topological reliability and resilience in the network either for individual nodes or on a subsystem or system level.
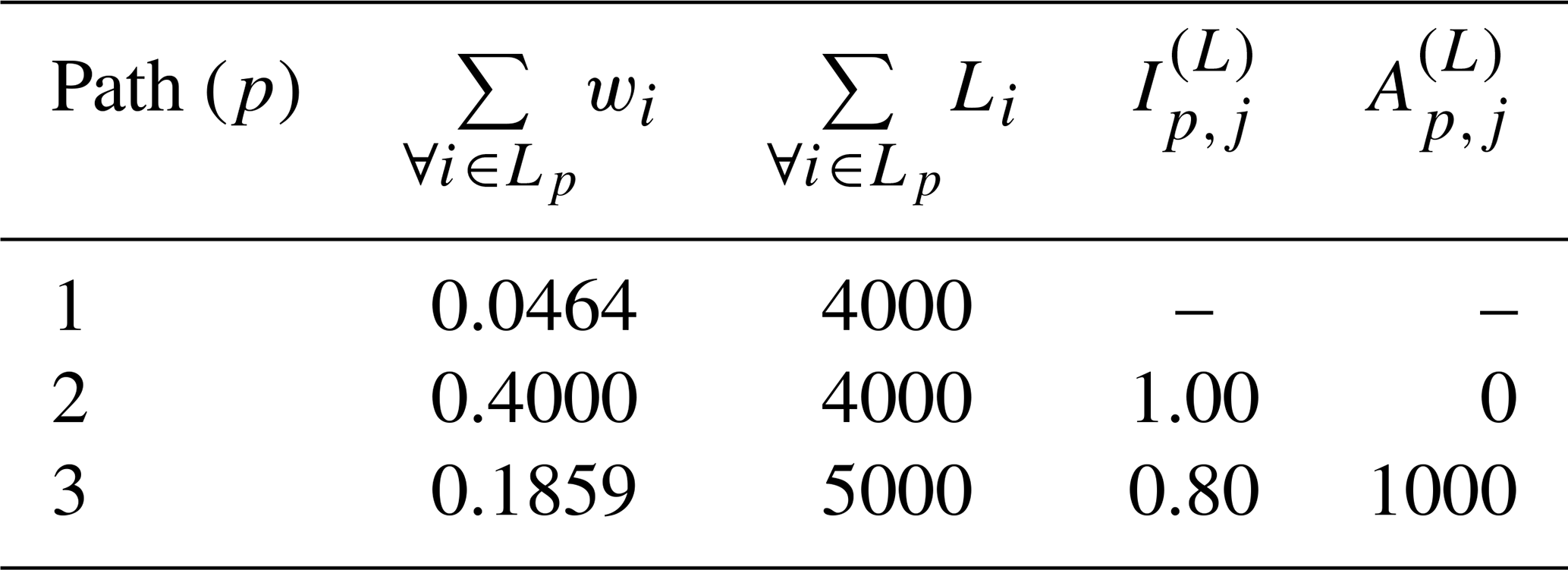
When P paths have been identified for any given node j, one can assess the degree of independence the paths to this node have from each other, by comparing which elements the pth path has to its preceding paths. This can be calculated as follows through the p-path independence proportion Ip,j:
where is some measure of distance for link i and may, for instance, pipe length Li or the probability of failure for each link i. As shown in Eq. (1), this index calculates the total length of elements in path that are also present in any of the preceding paths (i.e. elements that are not independent), and it divides it with the total length of the path.
Hence, a value means that the pth path to node j shares none of the links from any of the preceding paths, and it is therefore a supply to node j which is completely independent of any of the other paths. Conversely, if , it means that all of the links in the pth path to j are already present in one (or more) of the preceding paths, and that path p does not provide any supply redundancy to j.
The independence of the pth path can also be expressed in absolute terms:
where is the length the p shortest path to node j shares with a preceding path.
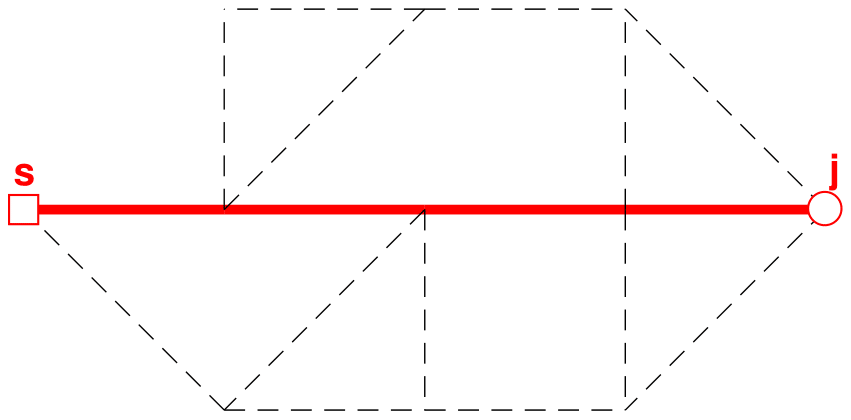
Figure 5First shortest path from s to j (solid line shows links in path, while dashed lines are not in path).

Figure 6Graph with updated weights after first shortest path is identified (thick grey lines indicate edges with updated weights).
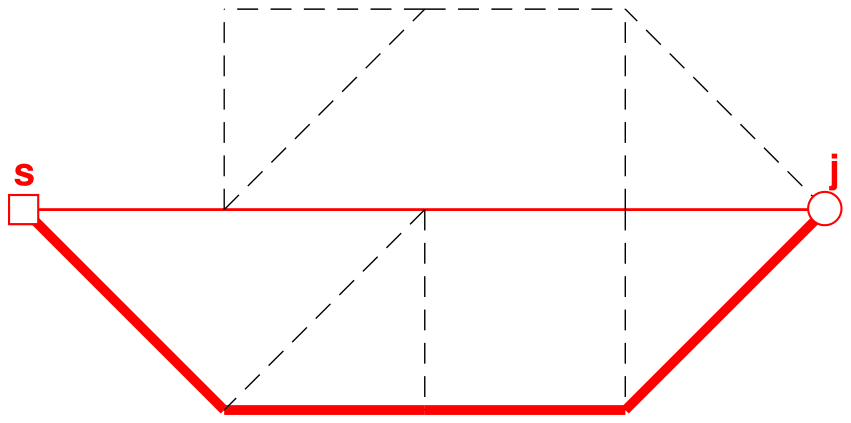
Figure 7First and second shortest paths from s to j (illustrated with thin and thick solid lines, respectively).
2.2.3 Simple network example
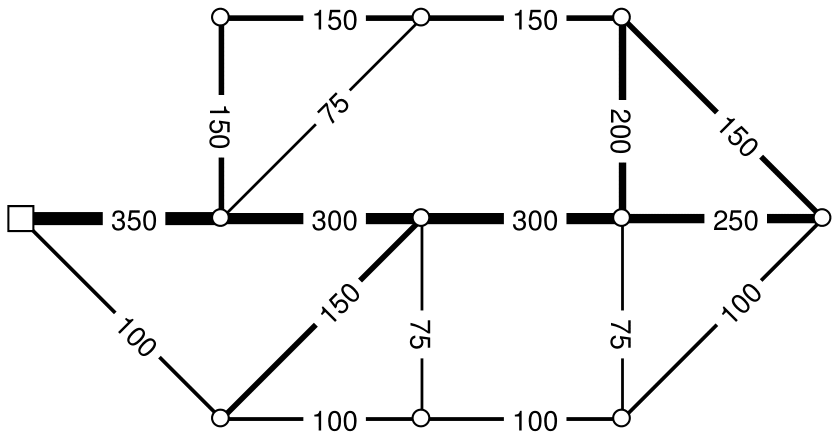
To illustrate how the suggested method in Fig. 2 works, a fictitious example network is used (Fig. 3), and the P shortest paths between a single source s and one node in this network is illustrated, identifying only the three shortest paths. This example network has pipe diameters according to Fig. 3, and all pipes are assumed to have the same length (L=1000 m) and friction factor (f=1). The steps undertaken to identify the P paths between two nodes (s and j) are as follows:
-
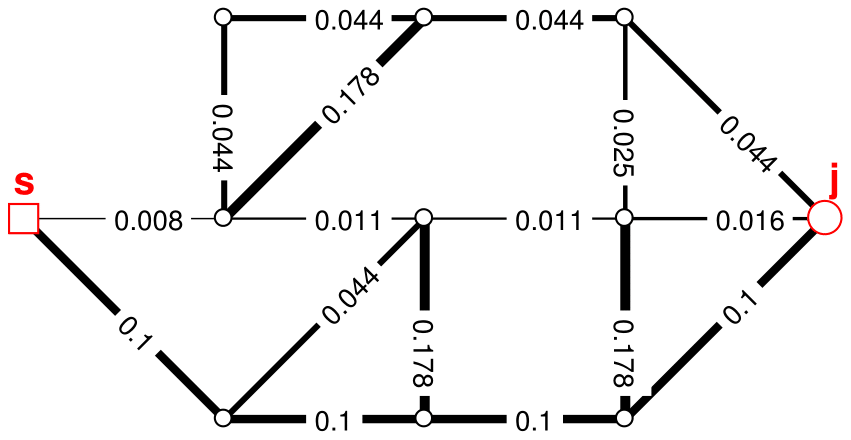
Step 1–2. Based on the network properties (pipe diameters and lengths), the weight of each edge is calculated, and the weighted bi-graph is constructed, as illustrated in Fig. 4. (Although a bi-graph is constructed, only one link between each node pair is visible in the example figures for simplicity of illustration.)
-
Step 3. When starting the process of identifying the shortest paths to a new node j, a copy of the weighted graph is made ().
-
Step 4–5. The shortest path between s and j is identified using the shortest-path algorithm, yielding a result as shown in Fig. 5.
-
Step 6. The weights of the links that are in this path are updated and given a high weight, as illustrated in Fig. 6, and the algorithm returns to step 4.
-
Step 4(2). The shortest-path algorithm is used again, with the altered weights, identifying the shortest path between s and j, avoiding the links that have already been identified in previous paths, yielding a result as shown in Fig. 7.
-
If further paths to node j are to be identified, the weights are updated again (see Fig. 8), and the shortest-path algorithm is used again to find the next shortest path (Fig. 9). This process is continued until the P shortest paths have been identified.
Table 1 shows the results from the analysis of the three shortest paths from s to j. The indicators and show that the algorithm has been able to identify two paths which are completely independent of each other (paths 1 and 2), since , and one path that is partially independent from the two preceding paths (path 3; ).
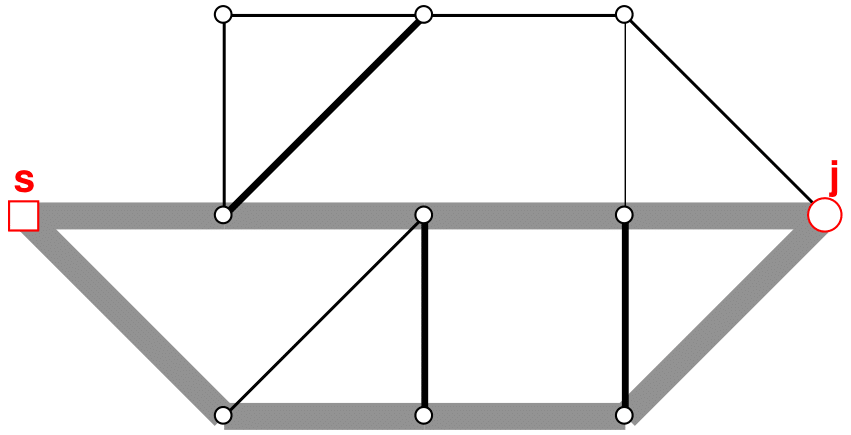
Figure 8Graph with updated weights after first and second shortest path are identified (thick grey lines indicate edges with updated weights).
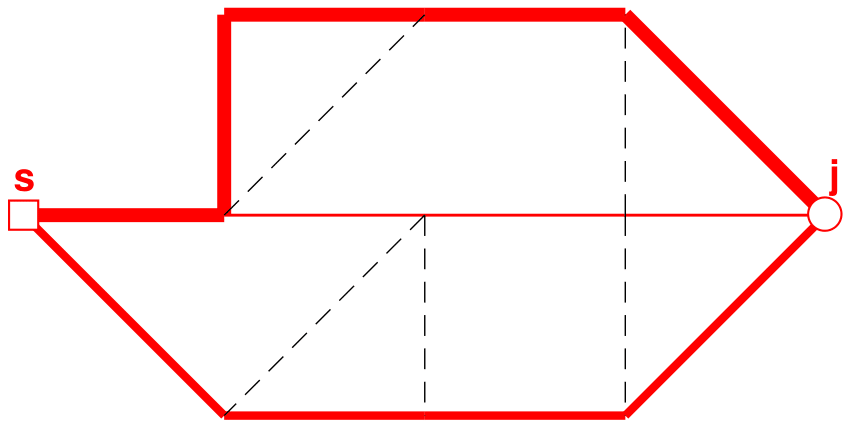
Figure 9First, second and third shortest paths from s to j (sorted from thinnest to thickest solid lines, respectively).
Table 1Summary of results for the three shortest-path analyses from s to j, Fig. 4.
2.3 Max flow algorithm-based variator that guides towards nearby minimal costs
The objective of the technique proposed here is to enhance the basic EA approach for sectorization with an additional variator. When applied to a given solution during the process, this variator picks one DMA from the solution and searches for nodes in its vicinity that may be optimal to include in it, based on the local network topology. On its own, the variator creates a greedy searching behaviour around a solution, accepting the macroscopic structure of the DMAs and specifically aiming to reduce the number of boundaries between them. It is assumed that by carefully managing the rate at which this hybrid variator is applied to parts of individual solutions, solutions can be seeded with optimal substructures, while the other, basic variators provide enough variation to avoid early convergence to local optima.
2.3.1 Algorithm outline and simple network example
The individual steps of the variator are outlined below and illustrated in Fig. 10. The lettered list matches the labels in the figure:
- A.
The algorithm chooses a specific DMA (light grey node cluster) and takes note of its boundaries (red links) with the rest of the network (white nodes).
- B.
Every non-DMA node within a certain distance of the t DMA is found (dark grey nodes). The links that connect two nodes from this selection are collected as well. The subgraph that is formed by these nodes and links is used in the next steps.
- C.
The isolated subgraph is expanded with the links that originally connected the subgraph to the DMA (blue lines), which are instead connected to a virtual source node. Moreover, the isolated subgraph is expanded with the links that originally connected the subgraph to the rest of the network (red lines), which are instead connected to a virtual source node.
- D.
The Edmonds–Karp max flow algorithm (Dinic, 1970) is used to find the maximum number of independent paths (green lines) from the virtual source to the virtual sink through the isolated subgraph.
- E.
The nodes in the isolated subgraph that can be reached from the virtual source without using any link in the independent paths found in step D are found with a breadth first search from the source (blue nodes).
- F.
In the original DMA configuration, the nodes found in step E are assimilated into the original DMA.
In effect, the algorithm searches for local imperfections in the interface between the DMA and the rest of the network.
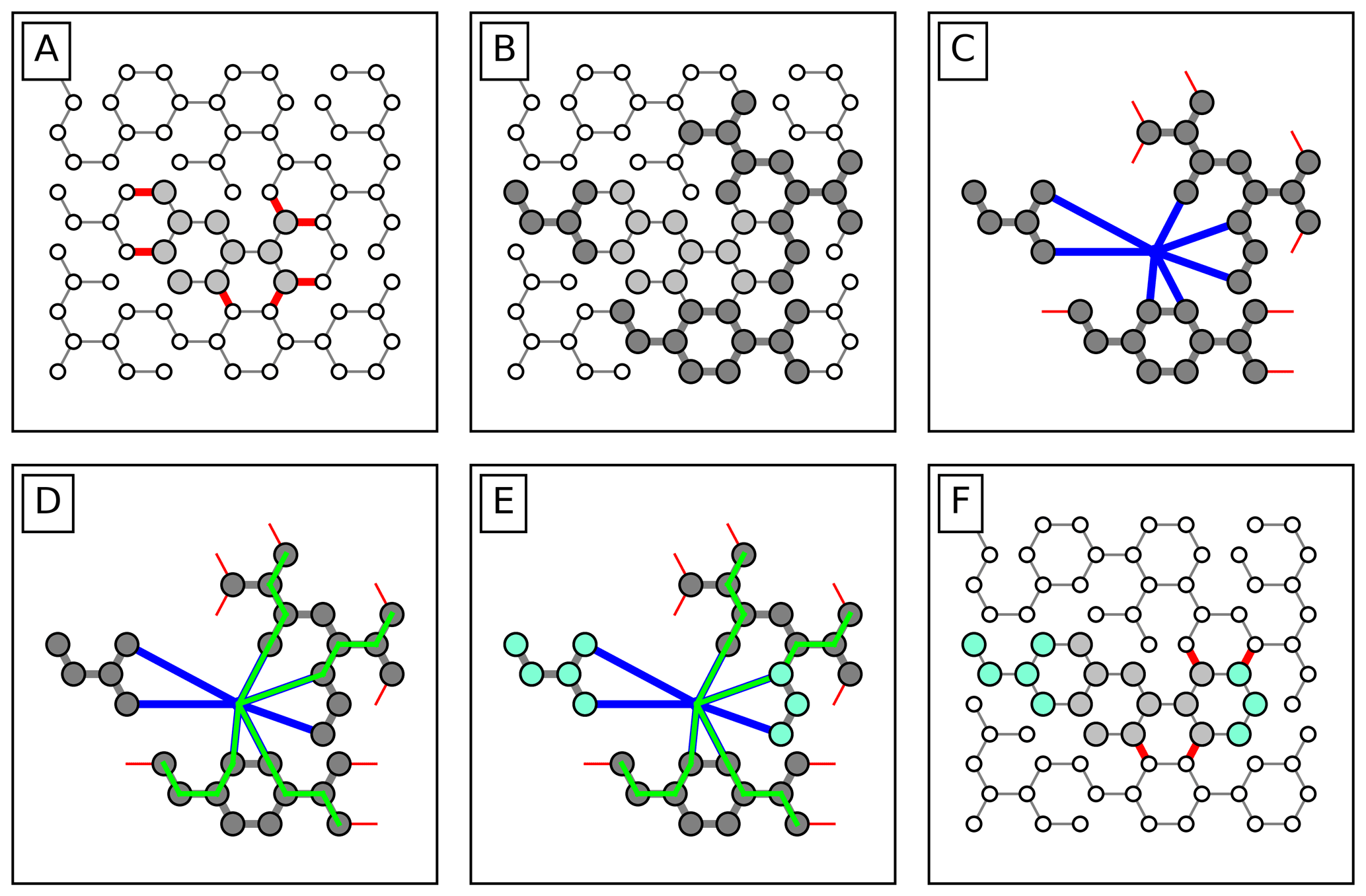
Figure 10Conceptual steps made by the hybrid variator to reduce the number of boundaries of a specific DMA by assimilation certain nearby nodes. The individual steps are explained in more detail in the text.
Firstly, boundaries that lead to the same “choke point” a few nodes away can be reduced by including the nodes up to the choke point (such as is the case for the assimilated node cluster on the right in the example). Achieving the same through random splitting and merging of the DMA and its neighbouring DMAs would take many generations in the EA.
Secondly, tiny DMAs that fall within the isolated subgraph entirely are joined to the DMA (such as the assimilated node cluster on the left in the example). This deliberately eradicates small node clusters from the solution, which would eventually occur through random merging otherwise.
Combined, these effects optimize the number of boundaries with minimal changes to the original DMA. The exact extent of the changes allowed can be controlled by choosing the depth of the subgraph around the DMA, which can be used as a parameter of the optimization algorithm.
2.3.2 Case study
The performance of this approach was tested within the context of a case study involving the optimization of a real DWDS: the network of the city of The Hague, in the supply area of the Dutch water utility Dunea. At the moment of writing, The Hague's network is strongly meshed and has no DMAs implemented, other than one pilot DMA that separates ∼2000 customers from the other ∼48 000. Dunea seeks to implement a DMA structure in The Hague as a part of their effort to better monitor the flow of their water supply.
The subdivision of this network into DMAs was originally optimized with a basic NSGA-II EA for two objectives: minimizing the total number of DMA boundaries and minimizing the maximum DMA size (in terms of daily peak demand). Further details about the background and definition of the original optimization problem were previously described in van Laarhoven and Gardien (2019).
Here, an optimization over a limited number of generations (100) was repeated for different combinations of rates of occurrence assigned to the variators (mutation through merging/splitting of a single DMA, crossover by combining DMAs from two solutions and application of the hybrid variator described above to a single DMA). In the first tests (EA1 to EA9), only mutation and crossover were applied to roughly scan for the most advantageous basic settings. Then, for the most advantageous combination of basic mutation and crossover, additional tests (HGA1 to HGA4) were performed with varying rates of the hybrid variator included. The performed tests are summarized in Table 2.
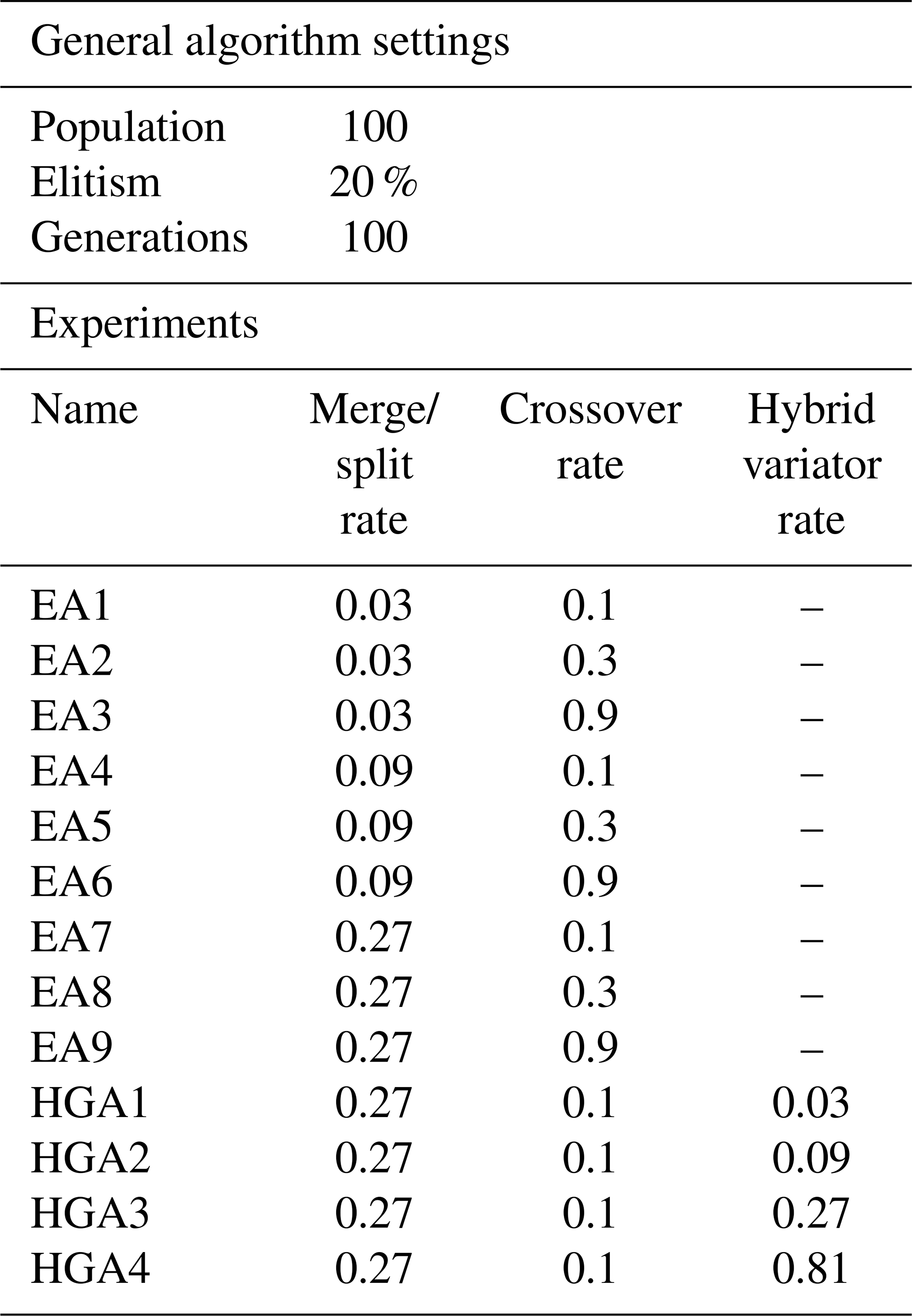
The results of each test were abstracted in terms of the quality of the Pareto front (hypervolume; Cao et al., 2015) with respect to the network's combined base demand and the maximum number of boundaries between DMAs allowed by the optimization: 4413 m3 h−1 and 500 boundaries, respectively. This allows us to investigate the influence of the hybrid variator on searching behaviour. The computational time of each test was registered to gain insight into the computational cost associated with the use of the hybrid variator. Each test was performed in triplicate to account for reproducibility.
3.1 Result of shortest-path analyses
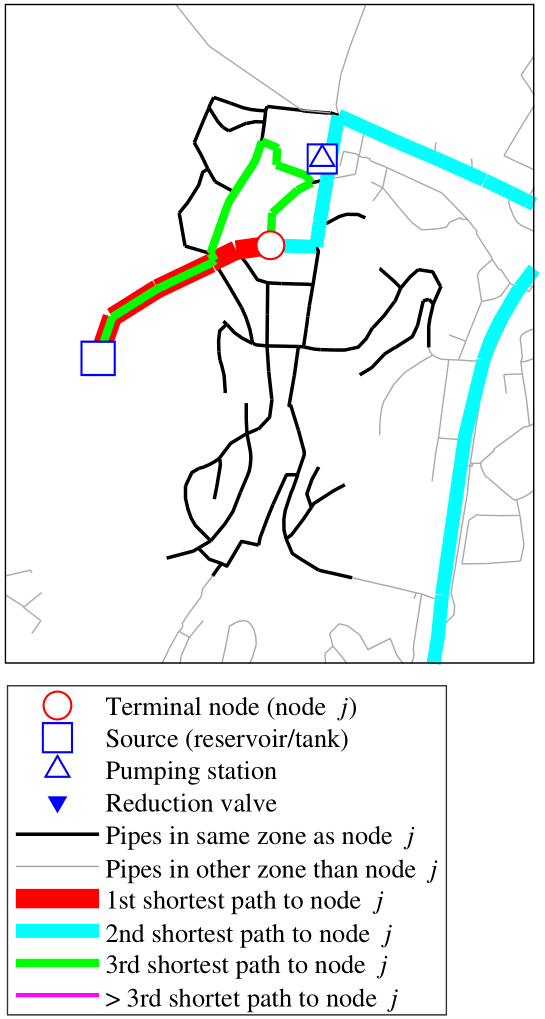
An example result from the shortest independent path analyses performed on Trondheim's DWDS is demonstrated in Fig. 11. In this example, the three shortest independent paths from available sources to one example node, j, have been identified. Node j is situated centrally in a small pressure zone in the periphery of Trondheim's DWDS. The analysis shows that the hydraulically closest source supplying node j is the reservoir situated in the west of the pressure zone; the path from this source to node j is indicated with a thick red line. Although there are multiple paths from the local reservoir to node j which are shorter than the second shortest path identified (cyan line), the second shortest path is the only path which is completely independent of the first shortest path identified, as there are no paths which are completely independent of each other from the reservoir to node j. After the first and second shortest independent paths have been identified, the algorithm finds that there are no additional completely independent paths to node j remaining, and it therefore seeks to find the path which shares the minimum path length with the previously identified paths. The third shortest path (green line) shares a subset of its path with the first shortest identified, but the algorithm seeks to find the solution where the first and third path has the minimum length of elements in common. The results derived from the independent path search can be used as a constraint when optimizing the allocation of flow-altering valves in a DWDS.
The results obtained for the independent paths in a DWDS can be compared to the more traditional “maxflow” value measure. When the maxflow between all sources and a node in DWDS is calculated for an unweighted graph, the resulting maxflow value is equal to the number of completely independent paths between the sources and the node in question. Summarized for Trondheim's DWDS, Fig. 12 demonstrates the relation between the MF value between sources and each node in the system, as well as the length of the path limiting each node from achieving a higher max flow value. The system contains roughly 4700 nodes which only have one completely independent path from a source (red area in Fig. 12). However, as the black line demonstrates, there are less than 2000 of these nodes where the first and second shortest path share more than 1 km of the path. Conversely, one can see from Fig. 12 that there are a few hundred nodes for which the single flow paths (where the first and second shortest paths are shared) are longer than 5 km. Thus, the results in Fig. 12 demonstrate how the proposed independent path measures can be used as a supplement to metrics describing one-sided or multi-sided supply in DWDSs.
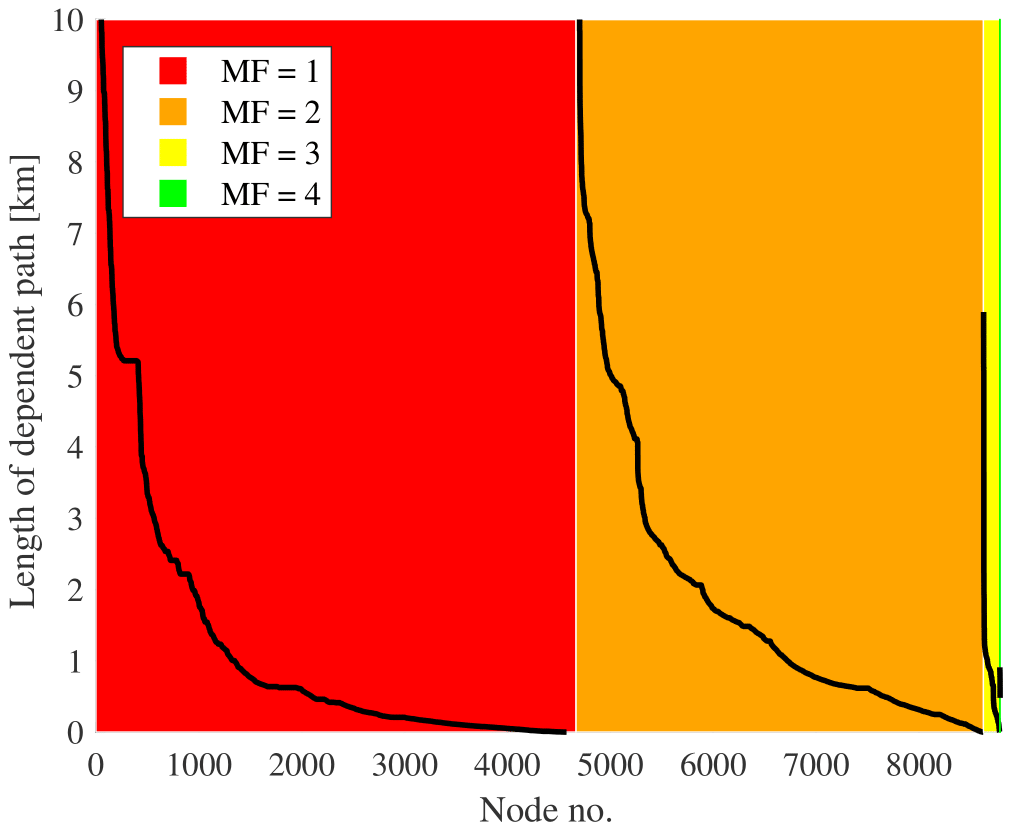
Figure 12Relation between MF and the length of path limiting the MF value for each node in Trondheim's DWDS.
3.2 Result of the max flow variator case study
Figure 13 summarizes the combined results of the experiments. The performances of all solutions in the Pareto fronts of all experiments are plotted, grouped only by colour in terms of whether the hybrid variator was used or not. From this, it becomes apparent that, indeed, the algorithm is able to produce a set of solutions of significantly higher quality in the same number of iterations when the hybrid variator is used. At smaller DMA sizes, the number of DMA boundaries is reduced by 50–100. Especially from a practical point of view, this is a substantial increase in quality if one considers that the realization of only a single DMA boundary may already cost a water utility thousands of euros.
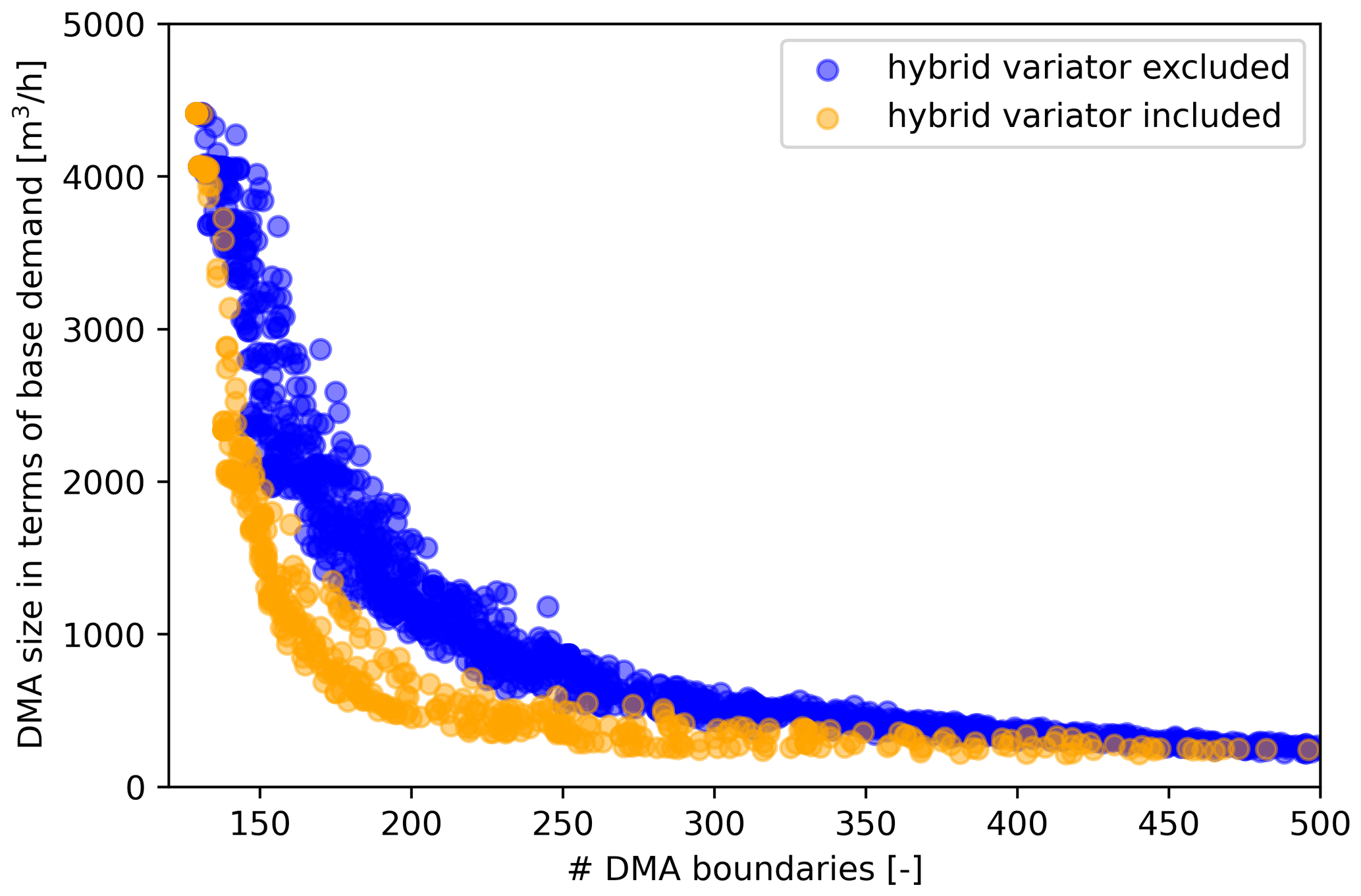
Figure 13Solutions of the Pareto fronts that followed from the experiments summarized in Table 2. Blue corresponds to the results from EA1 to EA9; orange corresponds to the results from HGA1 to HGA4.
The hypervolumes of the individual Pareto fronts are plotted against the computation times that were required to produce them in Fig. 14. Experiment EA7 produced the lowest average Pareto volume while also having one of the lowest computational times of the basic experiments. Hence, the settings for the merge, split and crossover rates of EA7 were used in the HGAx experiments as well.
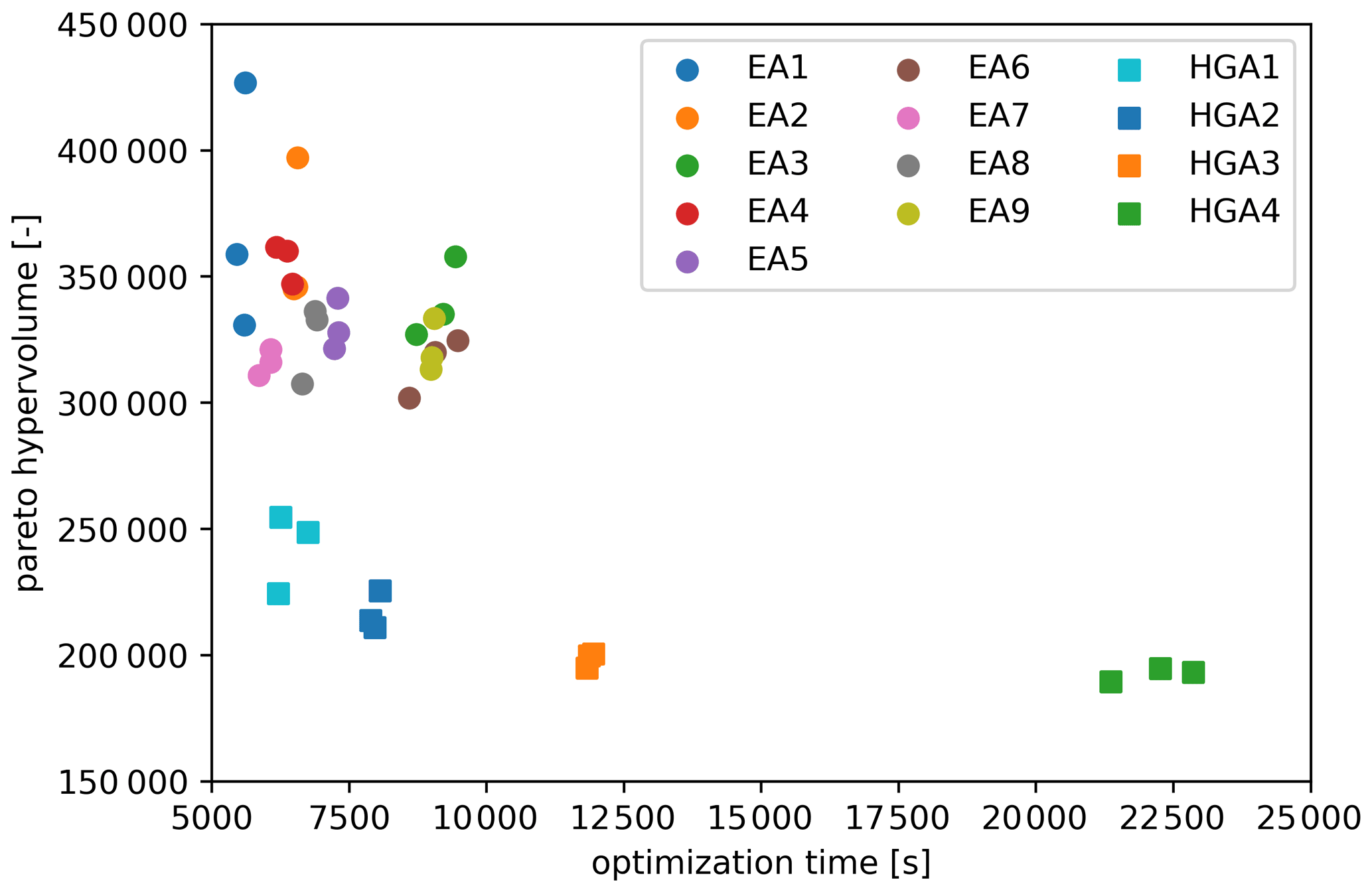
Figure 14The results of the experiments, which are summarized as the hypervolumes produced and plotted against the computation time (each experiment was performed in triplicate).
The data demonstrate that using the hybrid variator with a rate of occurrence of only a few percent already leads to a substantial decrease in hypervolume (increase in quality). The quality can be increased with higher rates of occurrence, but this comes at a significant cost of computational time: HGA4 takes around 5 times longer than HGA1.
For the past decade, graph theory has become an increasingly popular tool for analysing and optimizing the performance of DWDSs. Among other things, graph theory has been used as a computationally efficient means for optimally sectorizing DWDSs into DMAs or other subnetworks. In most of the cases, graph-theory-derived concepts – such as modularity indices, meshedness, centrality, algebraic connectivity, nodal degree, network density and so on – have been used as metrics to assess the efficiency and resilience of sectorization solutions, either during the optimization process or during a pre-processing step in which assumed optimal “building blocks” of DMAs are identified (Khoa Bui et al., 2020). These approaches rely on a common assumption: that these theoretical, graph-theory-based heuristics are in some way congruous with practical DWDS performance and therefore beneficial as a driver for optimization. The techniques described in this chapter were designed to exploit graph theory concepts without the need for such an assumption, keeping the objectives and constraints explicitly defined in terms of the strategic goals of the water utility expert: a minimum number of required interventions (boundaries) while hydraulic function is ensured.
The results presented in this paper represent computationally quick ways of solving sectorization problems, while at the same time considering specific practical constraints. The shortest-path algorithm presented in Sect. 2.2 can be used as a pre-processing step that ultimately excludes pipes as viable locations for pressure control zone boundaries, with practical requirements and regulations in mind. This provides an approach to use EAs for optimizing the design of pressure reduction zones – while guaranteeing acceptable performance under a multitude of possible failure scenarios – in a way that is computationally feasible.
The hybrid variator presented in Sect. 2.3 can be used (sparingly) in addition to other variators to add a local search component to the search behaviour that contributes to finding stronger solutions more quickly with EAs (as shown in Fig. 13). The variator can be used more rigorously to find even stronger solutions at the cost of substantial computational time (as shown in Fig. 14). As a result, the variator can be a valuable additional asset when applying EAs in the water utility practice to optimize the design of DMAs.
The shortest-path algorithm presented in Sect. 2.2 essentially constitutes a search space reduction with a specific DMA functionality in mind, and the hybrid variator presented in Sect. 2.3 essentially constitutes a greedy optimization step towards a specific DMA property. Although the initial results look promising and are able to provide results that are suitable for the water utility practice, both approaches increase the risk for the optimization to get stuck in local optima (i.e. to arrive at solutions that are “very good” but not “the best achievable”). Future work should focus on further elucidating this potential trade-off.
The code used for the The Hague case study was created under the general terms and conditions of the BTO joint research programme of the Dutch water utilities, which does not allow for source code to be made publicly available. Similarly, the code used for the Trondheim case study is restricted from public access due to the terms and conditions applied from the funding source.
The data used to support the findings presented in this paper are not available for sharing, due to the fact that the data describe details about actual water distribution systems, which are considered a critical infrastructures.
MMR designed the approach described in Sect. 2.2 and executed the case study described in Sect. 3.1. KvL designed the approach described in Sect. 2.3 and executed the case study described in Sect. 3.2. MMR and KvL prepared the article.
The contact author has declared that neither they nor their co-author has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors thank Dennis Gardien, Ina Vertommen and Peter van Thienen for their roles in the Dutch case study and Odd Atle Tveit, Birgitte G. Johannessen and Rannveig Høseggen for their roles in the Norwegian case study.
Part of this research was funded by the BTO joint research programme of the Dutch water utilities. The research was also partly funded through the Universitetskommune collaboration between the Norwegian University of Science and Technology and Trondheim municipality.
This paper was edited by Luuk Rietveld and reviewed by two anonymous referees.
Alvisi, S.: A New Procedure for Optimal Design of District Metered Areas Based on the Multilevel Balancing and Refinement Algorithm, Water Resour. Manage., 29, 4397–4409, https://doi.org/10.1007/s11269-015-1066-z, 2015.
Brentan, B., Campbell, E., Goulart, T., Manzi, D., Meirelles, G., Herrera, M., Izquierdo, J., and Luvizotto, E.: Social Network Community Detection and Hybrid Optimization for Dividing Water Supply into District Metered Areas, J. Water Resour. Pl. Manage., 144, 4018020, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000924, 2018.
Cao, Y., Smucker, B. J., and Robinson, T. J.: On using the hypervolume indicator to compare Pareto fronts: Applications to multi-criteria optimal experimental design, J. Stat. Plan. Infer., 160, 60–74, https://doi.org/10.1016/j.jspi.2014.12.004, 2015.
Ciaponi, C., Murari, E., and Todeschini, S.: Modularity-Based Procedure for Partitioning Water Distribution Systems into Independent Districts, Water Resour. Manage., 30, 2021–2036, https://doi.org/10.1007/s11269-016-1266-1, 2016.
Diao, K., Zhou, Y., and Rauch, W.: Automated Creation of District Metered Area Boundaries in Water Distribution Systems, J. Water Resour. Pl. Manage., 139, 184–190, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000247, 2013.
Diao, K., Fu, G., Farmani, R., Guidolin, M., and Butler, D.: Twin-Hierarchy Decomposition for Optimal Design of Water Distribution Systems, J. Water Resour. Pl. Manage., 142, C4015008, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000597, 2016.
di Nardo, A., Di Natale, M., Santonastaso, G. F., Tzatchkov, V. G., and Alcocer-Yamanaka, V. H.: Water Network Sectorization Based on Graph Theory and Energy Performance Indices, J. Water Resour. Pl. Manage., 140, 620–629, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000364, 2014.
Dinic, E. A.: Algorithm for Solution of a Problem of Maximum Flow in a Network with Power Estimation, Sov. Math Dokl., 11, 1277–1280, 1970.
El-Mihoub, T. A., Hopgood, A. A., Nolle, L., and Battersby, A.: Hybrid Genetic Algorithms: A Review, Eng. Lett., 13, 124–137, 2006.
Farley, M., Water, S., Supply, W., Council, S. C., and Organization, W. H.: Leakage management and control: a best practice training manual, World Health Organization, Geneva, Switzerland, https://apps.who.int/iris/bitstream/handle/10665/66893/WHO_SDE_WSH_01.1_eng.pdf (last access: 10 June 2022), 2001.
Goldberg, D. E.: Genetic algorithms in search Optimization, and MachineLearning, 1st Edn., Addison-Wesley Professional, ISBN 978-0201157673, 1989.
Hajebi, S., Roshani, E., Cardozo, N., Barrett, S., Clarke, A., and Clarke, S.: Water distribution network sectorisation using graph theory and many-objective optimisation, J. Hydroinform., 18, 77–95, https://doi.org/10.2166/hydro.2015.144, 2015.
Holland, J.: Adaptation in Natural and Artificial Systems, U Michigan Press., Michigan, USA, ISBN 978-0262581110, 1975.
Khoa Bui, X., S. Marlim, M., and Kang, D.: Water Network Partitioning into District Metered Areas: A State-Of-The-Art Review, Water, 12, 1002, https://doi.org/10.3390/w12041002, 2020.
Kim, J., Hwang, I., Kim, Y.-H., and Moon, B.-R.: Genetic approaches for graph partitioning: a survey, Association for Computing Machinery, New York, NY, USA, ISBN 9781450305570, https://doi.org/10.1145/2001576.2001642, 2011.
Krasnogor, N. and Smith, J.: A tutorial for competent memetic algorithms: model, taxonomy, and design issues, IEEE T. Evol. Comput., 9, 474–488, https://doi.org/10.1109/TEVC.2005.850260, 2005.
Laucelli, D. B., Simone, A., Berardi, L., and Giustolisi, O.: Optimal Design of District Metering Areas for the Reduction of Leakages, J. Water Resour. Pl. Manage., 143, 4017017, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000768, 2017.
Liu, J. and Han, R.: Spectral Clustering and Multicriteria Decision for Design of District Metered Areas, J. Water Resour. Pl. Manage., 144, 4018013, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000916, 2018.
Maier, H. R., Kapelan, Z., Kasprzyk, J., Kollat, J., Matott, L. S., Cunha, M. C., Dandy, G. C., Gibbs, M. S., Keedwell, E., Marchi, A., Ostfeld, A., Savic, D., Solomatine, D. P., Vrugt, J. A., Zecchin, A. C., Minsker, B. S., Barbour, E. J., Kuczera, G., Pasha, F., Castelletti, A., Giuliani, M., and Reed, P. M.: Evolutionary algorithms and other metaheuristics in water resources: Current status, research challenges and future directions, Environ. Model. Softw., 62, 271–299, https://doi.org/10.1016/j.envsoft.2014.09.013, 2014.
Mala-Jetmarova, H., Sultanova, N., and Savic, D.: Lost in optimisation of water distribution systems? A literature review of system design, Water, 10, 307, https://doi.org/10.3390/w10030307, 2018.
Morrison, J., Tooms, S., and Rogers, D.: DMA Management Guidance Notes, International Water Association (IWA), Specialist Group Efficient operation and Management Water Loss Task Force, London, UK, https://iwa-network.org/learn_resources/district-metered-areas-guidance-notes/ (last access: 10 January 2017), 2007.
Rossman, L.: Epanet 2.0 User's Manual, Water Supply and Water Resources Division, US Environmental Protection Agency, US EPA, Cincinnati, https://nepis.epa.gov/Adobe/PDF/P1007WWU.pdf (last access: 10 June 2022), 2000.
UK Water Authorities Association: Report 26 Leakage Control Policy & Practice, Ofwat, London, UK, https://www.dwi.gov.uk/research/completed-research/drinking-water-distribution-networks/leakage-control-policy-and-practice/ (last access: 10 January 2017), 2008.
van Laarhoven, K., Vertommen, I., and van Thienen, P.: Technical note: Problem-specific variators in a genetic algorithm for the optimization of drinking water networks, Drink. Water Eng. Sci., 11, 101–105, https://doi.org/10.5194/dwes-11-101-2018, 2018.
van Laarhoven, K. A. and Gardien, D.: How to detect as many leaks as possible with as few flow meters as possible?, 12–15, 2019.
van Thienen, P., Vertommen, I., and van Laarhoven, K.: Practical application of optimization techniques to drinking water distribution problems, in: HIC 2018, vol. 3, 13th International Conference on Hydroinformatics, 1–6 July 2018, Palermo, Italy, 2136–2143, https://doi.org/10.29007/b54r, 2018.
Vasilic, Ž., Stanic, M., Kapelan, Z., Prodanovic, D., and Babic, B.: Uniformity and Heuristics-Based DeNSE Method for Sectorization of Water Distribution Networks, J. Water Resour. Pl. Manage., 146, 04019079, https://doi.org/10.1061/(asce)wr.1943-5452.0001163, 2020.
Zhang, Q., Wu Zheng, Y., Zhao, M., Qi, J., Huang, Y., and Zhao, H.: Leakage Zone Identification in Large-Scale Water Distribution Systems Using Multiclass Support Vector Machines, J. Water Resour. Pl. Manage., 142, 4016042, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000661, 2016.
Zhang, Q., Wu Zheng, Y., Zhao, M., Qi, J., Huang, Y., and Zhao, H.: Automatic Partitioning of Water Distribution Networks Using Multiscale Community Detection and Multiobjective Optimization, J. Water Resour. Pl. Manage., 143, 4017057, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000819, 2017.